hadoop分布式集群搭建
hadoop分布式集群搭建
1. 创建三台虚拟机
虚拟机用的是CenOS 7镜像文件已打包好:
天翼云盘:https://cloud.189.cn/t/bQr6VrB7Zzmu(访问码:1ck6)
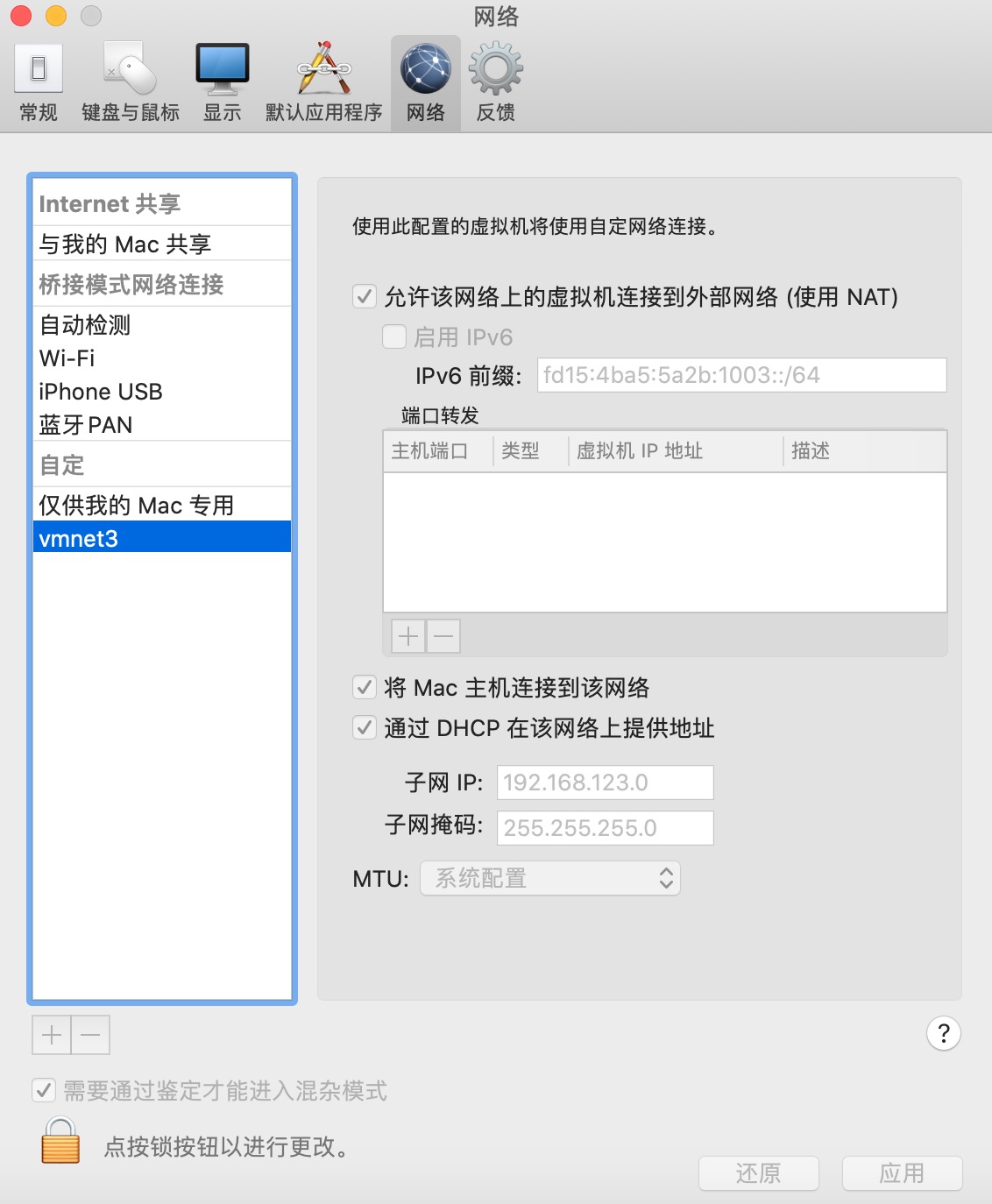
2. 创建子网:将三台虚拟机的IP连接到子网中。
进入子网配置界面:VMware Fusion > 偏好设置 > 网络。
根据自己喜好,划分一个子网:
A类保留地址:10.0.0.0 ~ 10.255.255.255
B类保留地址:172.16.0.0 ~ 172.31.255.255
C类保留地址: 192.168.0.0 ~192.168.255.255
查看子网:
1 | # 我的子网IP设置为:192.168.120.0 |
查看网关:
1 | # 网关IP默认为:192.168.120.2 |
3. 配置虚拟机静态IP
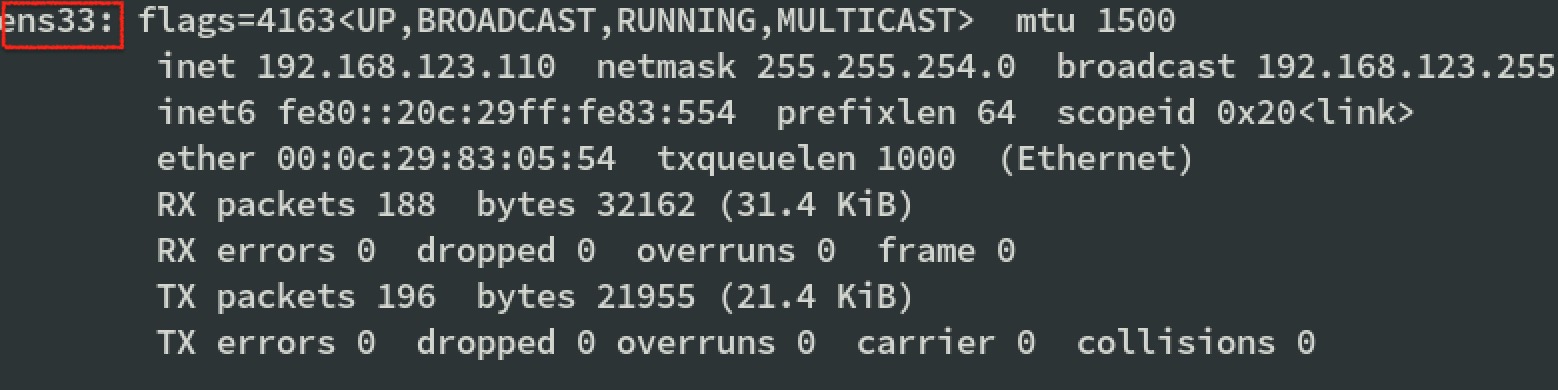
修改hadoop的网络(以hadoop01为例)
1 | vim /etc/sysconfig/network-scripts/ifcfg-ens33 |
重启网络
1 | service network restart |
修改hadoop02和hadoop03的IP。我分配的IP分别是:
hadoop01: 192.168.120.110
hadoop02: 192.168.120.120
hadoop03: 192.168.120.130
4. 设置hadoop主机名:
1 | hostnamectl set-hostname hadoop01 |

修改hadoop02和hadoop03的主机名。
5. 配置内网域名映射:
1 | vim /etc/hosts |
6. 配置ssh免密登录(以hadoop01为例):
生成密钥
1 | ssh-keygen -t rsa |
将密钥分配到hadoop02和hadoop03
1 | ssh-copy-id hadoop01 |

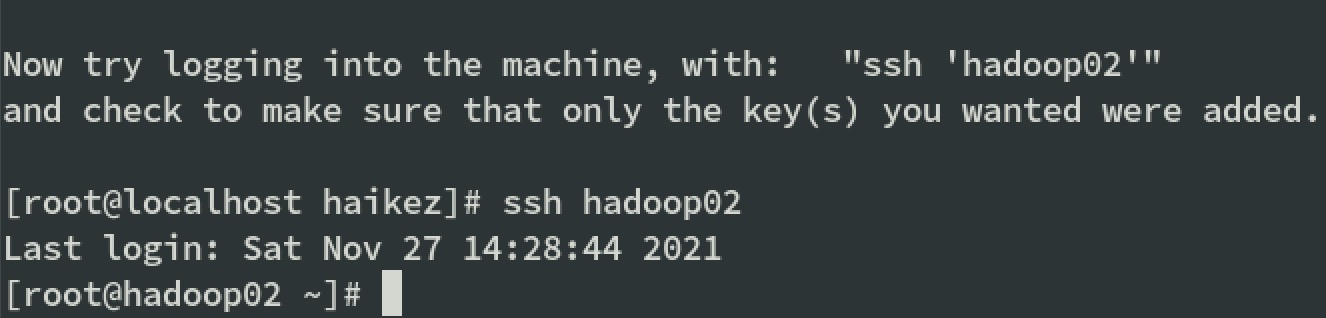
注意:还需要在hadoop02配置一下免登录到 hadoop01、hadoop02、hadoop03。还需要在hadoop03配置一下免登录到 hadoop01、hadoop02、hadoop03。
7. 防火墙
查询防火墙的命令:
1 | systemctl status firewalld |
临时关闭防火墙:(注意 临时关闭之后,服务器再次重启,防火墙会自动开启)
1 | systemctl stop firewalld |
永久关闭防火墙:(注意 先临时关闭,再永久关闭)
1 | systemctl disable firewalld |
8. 安装java
(1)、天翼云盘下载:
https://cloud.189.cn/t/AjAJZbiyYfAv(访问码:ms9z)
(2)、解压java的tar包
1 | tar -zxvf jdk-8u211-linux-x64.tar.gz -C /usr/local |

9. 安装hadoop集群
(1)、去官网下载:
https://hadoop.apache.org/
天翼云盘下载:
https://cloud.189.cn/t/367zaeiuEFfu(访问码:pjj1)
(2)、解压hadoop的tar包
1 | tar -zxvf hadoop-2.7.3.tar.gz -C /usr/local |

(3)、配置环境变量
1 | vim /etc/profile |
1 | export JAVA_HOME=/usr/local/jdk1.8.0_211 |
记得source
1 | source /etc/profile |
10. 配置文件的修改
1 | cd /usr/local/hadoop-2.7.3/etc/hadoop |
(1)、修改hadoop的依赖环境java
1 | vi hadoop-env.sh |
把jdk的依赖加进去就OK

(2)、配置hadoop的访问客户端
1 | vi core-site.xml |
1 | <configuration> |
(3)、配置元数据与真实数据的存储路径信息
1 | vi hdfs-site.xml |
1 | <configuration> |
(4)、配置计算框架mapreduce
先把临时的文件修改成非临时
1 | mv mapred-site.xml.template mapred-site.xml |
修改:
1 | vi mapred-site.xml |
1 | <configuration> |
(5)、修改yarn资源调度
1 | vi yarn-site.xml |
1 | <property> |
(6)、配置从节点
1 | vi slaves |
把localhost删掉,添加
hadoop02
hadoop03
11. 启动
(1)、分发
1 | scp -r /usr/local/jdk1.8.0_211 hadoop02:/usr/local/ |
(2)、初始化namenode (只执行一次)
1 | hadoop namenode -format |
(3)、启动
1 | start-all.sh |
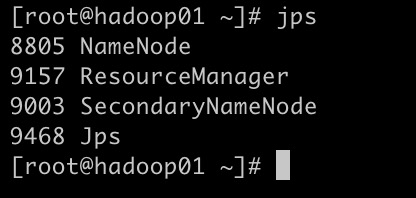
(4)、停止
1 | stop-all.sh |