1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
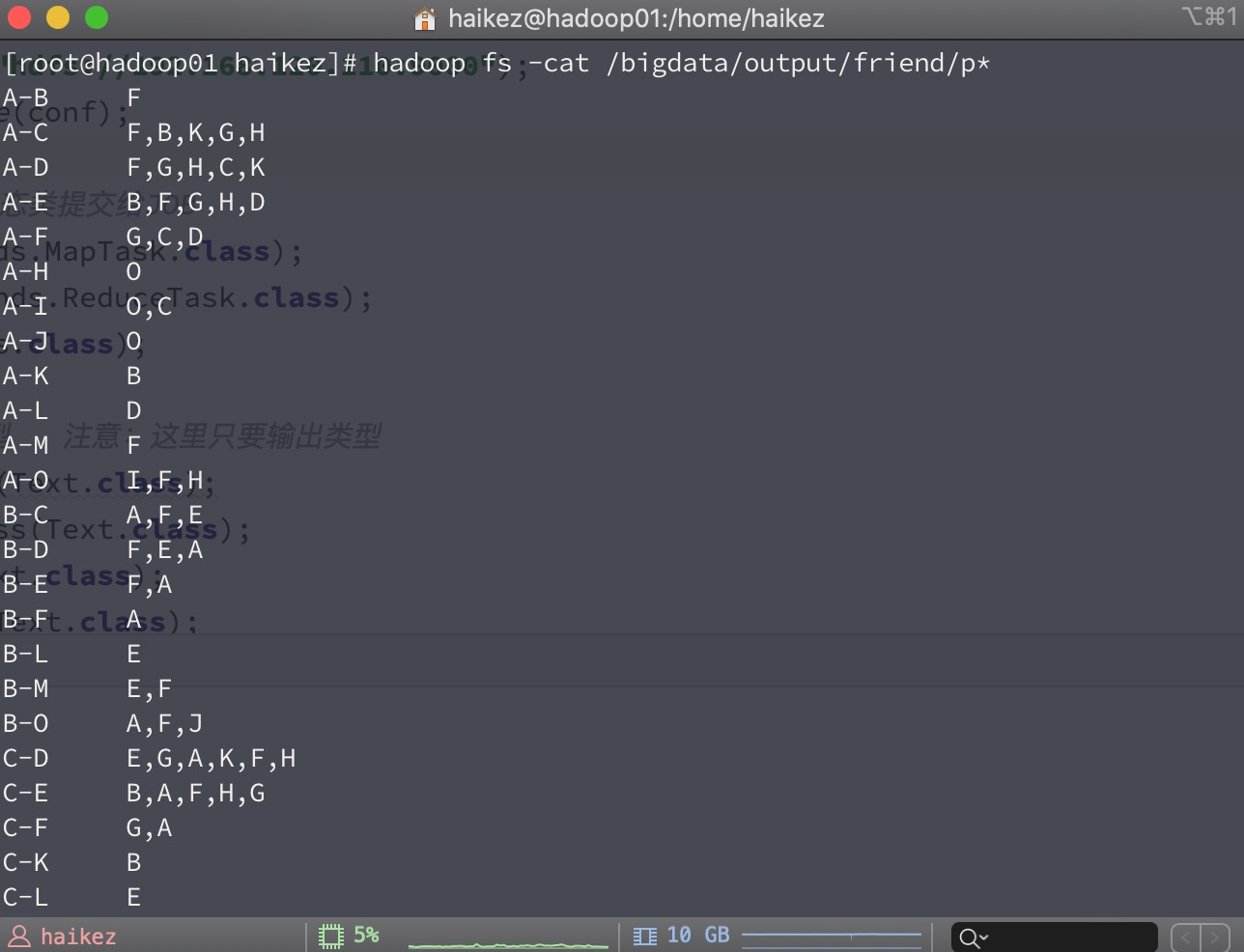
| package friends;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.Arrays;
public class Friends {
public static class MapTask extends Mapper<LongWritable, Text,Text,Text>{
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context) throws IOException, InterruptedException {
String[] split = value.toString().split(":");
String o_value = split[0];
String[] friends = split[1].split(",");
Arrays.sort(friends);
for (int i=0;i<friends.length-1;i++){
for (int j=i+1;j<friends.length;j++){
context.write(new Text(friends[i]+"-"+friends[j]),new Text(o_value));
}
}
}
}
public static class ReduceTask extends Reducer<Text,Text,Text,Text>{
@Override
protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException {
String str="";
int flag=0;
for (Text value : values) {
if (flag==0){
str+=value.toString();
flag++;
}else str+=","+value.toString();
}
context.write(key,new Text(str));
}
}
public static void main(String[] args) throws Exception {
System.setProperty("HADOOP_USER_NAME","root");
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://192.168.120.110:9000");
Job job = Job.getInstance(conf);
job.setMapperClass(Friends.MapTask.class);
job.setReducerClass(Friends.ReduceTask.class);
job.setJarByClass(Friends.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
String outPath="/bigdata/output/friend";
FileSystem fileSystem = FileSystem.get(conf);
if(fileSystem.exists(new Path(outPath))){
fileSystem.delete(new Path(outPath),true);
}
FileInputFormat.addInputPath(job,new Path("/bigdata/input/friend.txt"));
FileOutputFormat.setOutputPath(job,new Path("/bigdata/output/friend"));
boolean b = job.waitForCompletion(true);
System.out.println(b?"代码没毛病!!!":"出BUG,赶快看一下!!!");
}
}
|